Summary
We are going to implement a parallel version of Dijkstra algorithm on both PIM system and GPU, and compare between two kind of architecture on the Graph workload.
Work Done
Currently, we have implement the sequential version of the Dijkstra's algorithm using the CPU, and a initial version of the GPU version of the Dijkstra's algorithm.
There is a script to generate a random graph, and assigning a weight on each edge. The CPU and GPU version of the Dijkstra's algorithm will read the graph and generate the shortest path length from a starting point to all other points.
The GPU and CPU version have the same result, and thus our GPU version of the Dijkstra's algorithm is correct.
Some Result
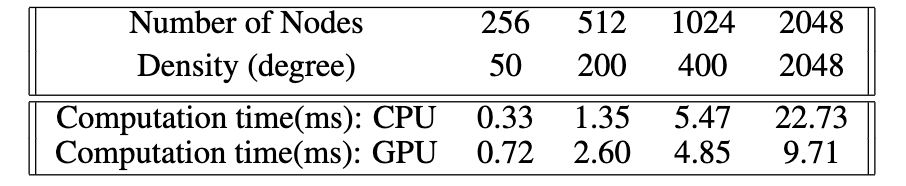
We implemented the GPU-parallel version using CUDA, and ran it on GHC machine. Here are the runtime results of GPU compared to CPU.
The GPU version works well when the graph is more dense.
Goal and Deliverable
Our basic goal is to implement the GPU and PIM version of the Dijkstra's algorithm. We believe we have enough time to develop the PIM version of the Dijkstra's algorithm, and thus being able to finish the PIM version of the Dijkstra's algorithm.
If there is still more time after we done our PIM version of the Dijkstra's algorithm, then we can use the openMP to further improve the speed of the algorithm.
The deliverables are the CUDA implementation and the PIM implementation of the algorithms, and analysis of our parallel implementation of the two architecture with comparison. We will show speedup graphs and profiling results, and discuss the results.
Show Case
In our poster, we will include the introduction to the PIM architecture, since it is a in-research architecture and not a commonly used architecture. We will also introduce the benefit of the PIM architecture.
We also include the scaling graph of the algorithm on each machine, and some performance statistic of the three version of the algorithm. From the statistic, we can include the analysis of each architecture for the algorithm.
Concern
Our main concern is that the performance of the GPU and PIM version of the Dijkstra's algorithm will not be out-perform the CPU sequential version of the algorithm. But it might be the case, since using the GPU version will complicate the algorithm, and might introduce more overhead than the speedup.